知光
认证双令牌模式
在知光APP中,采用Spring Security+JWT的双令牌机制,将短期的accessToken与长期的refreshToken 分离: accessToken负责高性能、无状态的接口访问认证 refreshToken负责长期会话的续期与控制。 这样既提升了账号安全性(缩小单次泄露的影响范围、支持强制下线与风控),又保证了用户的长期免登录体验,同时兼顾了分布式架构下的扩展性和会话管理能力。
什么是双令牌
accessToken(访问令牌)
作用: 每次访问业务接口时,用来证明“我是某某用户”。 比如你现在的 Authorization:Bearer xxx 就是 accessToken. 特点: 有效期很短(比如15分钟、30分钟) 内部自带用户ID、角色、权限等信息(JWT的payload)。 后端只需要校验签名和是否过期,一般不查数据库,性能好、扩展性强。 使用方式: 前端每次调/api/v1/xxx时带上它用以权限认证。
refreshToken (刷新令牌)
作用 不直接访问业务接口,只用来换取新的accessToken。当前accessToken过期了,前端拿refreshToken调/auth/refresh 这种接口,就能拿到一对新的accessToken + refreshToken. 特点: 有效期较长(比如7天、14天甚至30天)。 一般只在少数几个认证接口使用:/1ogin、/refresh。 可以结合Redis/数据库做黑名单、版本号等控制(更容易做“踢下线”注销”)。
为什么要用双令牌,而不是一个长有效期的token?
安全性更高 如果只有一个长生命周期的JWT: 比如你设一个JWT直接30天不过期,一旦这个token被窃取,黑客可以在30天内随便伪装成用户操作,风险非常大。 又因为JWT一般是“无状态”的,后端默认不会存储、也不回收,因此很难"立刻让这个token失效"双令牌的改进: accessToken只活15~30分钟--即使被盗,黑客最多用这一小段时间。 refreshToken一般只在“刷新接口”使用,你可以:
把refreshToken保存得更安全(比如HttpOnly Cookie、只在后端存一份、只允许HTTPS)针对refreshToken做更严格检查:设备信息、IP、User-Agent、单点登录等。 一旦发现泄露或用户手动“退出登录”,直接把对应的refreshToken在 Redis标记失效: 老的refreshToken无法再换新token; accessToken也会因为短时过期,自然失效; 这样就实现**“可控的强制下线”。** 短命的accessToken+ 受控的refreshToken,比一个长命JWT安全得多。
提升用户体验(减少频繁登录) 只有一个短期JWT时: 你为了安全,把过期时间设得很短(例如30分钟) 那用户会频繁被“踢回登录页面”,体验很差。双令牌的玩法是: accessToken失效后,前端用refreshToken悄悄调一次刷新接口,换一对新的;对用户来说,整个过程是“无感”的: 只要refreshToken还没过期,就能一直续命; 只有在refreshToken真正过期(比如7天不登录)之后,才需要重新输账号密码。
兼顾“无状态扩展性"和“可控的登录状态”
accessToken校验可以完全无状态(只靠签名+过期时间),非常适合分布式,集群部署: 任意一个服务实例都能根据JWT自己完成认证。 refreshToken可以是“轻状态”的: 把 refreshToken ID 存到 Redis; 可以做: 单点登录(同一用户只允许一个刷新token生效);
踢人下线(删除某个refreshToken记录);
安全风控(记录设备、IP,异常则禁止刷新)
这样就可以做到: 业务接口层(多服务)只管校验accessToken,不查库,性能高; 认证中心/网关少量存refreshToken的状态,用来集中管理登录会话,引入“可控的在线状态”。
大佬总结
https://pcn81psk6d0i.feishu.cn/wiki/OwoAwCdU3iKJDHkkSFOcprXRnOG
面试:
解释一下什么叫做双令牌模式
“双令牌模式就是把认证拆成两类令牌:Access Token 和 Refresh Token。 Access Token 短期有效,用于访问接口;Refresh Token 长期有效,只用于换新 Access Token。 这样做的好处是:既保证安全(短令牌泄露风险窗口小),又保证体验(用户不需要频繁登录),并且后端可以通过 Redis 对 Refresh Token 做吊销和强制下线管理。”
访问令牌与刷新令牌的有效期分别是多少?为什么这样设置
本项目里配置是:
Access Token
15 分钟
Refresh Token
7 天
为什么这么设:
Access Token
短有效期(15 分钟)
- 被窃取后的可利用窗口更短,安全性更高。
Refresh Token
长一些(7 天)
- 用户不用频繁重新登录,体验更好。
两者配合
- 短期凭证负责“安全”,长期凭证负责“续航”。
登录状态是无状态还是有状态?有什么区别?为什么这样选择?
本项目的登录状态不是纯粹的一种,而是 “访问态无状态,刷新态有状态” 的混合方案。
Access Token 是无状态的。后端不保存登录 session,每次请求只校验 JWT 本身,所以服务可以横向扩展,压力更小。
Refresh Token 是有状态的。虽然它也是 JWT,但项目把它的 jti 存到了 Redis 白名单里,刷新时不仅验签,还会查 Redis 是否存在,这样才能支持登出、单端失效、全端下线。
区别很简单:
- 无状态:服务端不存会话,性能和扩展性好,但 access token 一旦发出去,不容易立刻废掉。
- 有状态:服务端保存状态,能主动撤销,但会增加 Redis 依赖和状态管理成本。
为什么这样选:因为它同时兼顾了 性能 和 安全。高频请求走无状态 access token,减轻服务端压力;低频续签走有状态 refresh token,用 Redis 补上“可撤销、可踢下线”的能力。
.sessionManagement(session ->
session.sessionCreationPolicy(SessionCreationPolicy.STATELESS)
)签发 access token 的逻辑在 [JwtService.java]
Instant accessExpiresAt = issuedAt.plus(properties.getJwt().getAccessTokenTtl()); /**
* 将刷新令牌写入白名单,设置过期时间。
*
* @param userId 用户 ID。
* @param tokenId 刷新令牌 ID。
* @param ttl 生存时间(Redis TTL)。
*/
@Override
public void storeToken(long userId, String tokenId, Duration ttl) {
String key = key(userId, tokenId);
redisTemplate.opsForValue().set(key, "1", ttl);
}
/**
* 撤销单个刷新令牌。
*
* @param userId 用户 ID。
* @param tokenId 刷新令牌 ID。
*/
@Override
public void revokeToken(long userId, String tokenId) {
redisTemplate.delete(key(userId, tokenId));
}验证码是怎么做的?过期时间用什么做的
本项目的验证码是基于 Redis 实现的:服务端生成 6 位随机验证码后写入 Redis,并通过 TTL 控制 5 分钟过期;同时用 Redis 额外做 60 秒发送间隔限制和每日 10 次发送上限。校验时会校验验证码、记录输错次数,成功后立即删除,保证一次性使用。
过期时间是用 Redis 的 TTL 机制 做的。验证码保存到 Redis 后,会直接调用 expire(key, ttl) 设置生存时间,到了 5 分钟 Redis 会自动删除这个 key,不需要额外定时任务。
接口授权中,用户userid是怎么拿到的
@PatchMapping
public ProfileResponse patch(@AuthenticationPrincipal Jwt jwt,
@Valid @RequestBody ProfilePatchRequest request) {
long userId = jwtService.extractUserId(jwt);
return profileService.updateProfile(userId, request);
}接口授权里,userId 是从 JWT 访问令牌 里拿到的,不是前端手传的。避免前端自己传 userId 造成越权。服务端只信令牌里的身份。long userId = jwtService.extractUserId(jwt);
项目中是如歌对接口鉴权的?(要知道公告接口以及需要token鉴权的接口分别有哪些,怎么拦截鉴权的)
项目接口鉴权是基于 JWT 做的。公开接口,比如登录、注册、验证码、首页公开内容,会在安全配置里放行;其他接口默认都要求携带 token。请求进来后先由安全框架统一校验 token,校验通过后再从令牌里解析当前用户身份,业务代码全程使用服务端解析出的用户 ID,而不是信任前端传参,这样可以防止越权。
一、方案背景:高并发行为计数的核心痛点
在社交、电商等高频交互场景中,用户的点赞(like)、收藏(fav)、评论等行为会产生海量计数更新请求。“同步直写最终计数”的方案在高并发下暴露诸多致命问题,成为系统性能瓶颈,具体可归纳为三大核心痛点
(一)写热点与写放大问题突出
1.高频细粒度写入引发热点压力:用户每一次行为操作都直接写入最终计数存储,形成高频次、细粒度的写请求。热门实体(如爆款帖子、大V)的计数键会成为“热点行”,集中占用存储节点的CPU、IO资源,导致响应延迟飙升。 2.随机写加剧存储负担:不同指标(like/fav/comment)的独立更新的是同一实体的不同字段,会产生大量随机写操作。这不仅增加了存储层的IO开销(尤其是磁盘存储的随机寻道成本),还会引发严重的锁竞争,进一步放大尾延迟。 **3.网络与存储成本浪费:**单条行为的计数更新数据量极小,但高频请求会占用大量网络带宽;同时,存储层需要处理海量零散写请求,硬件资源利用率低,导致成本浪费。
(二)一致性与用户体验的平衡难题
用户行为计数场景存在**“双重需求矛盾”😗* 一方面,用户操作后需要"即时生效”的交互反馈(如点击点赞后立即显示“已点赞”状态),这要求用户维度的状态具备强一致性;
另一方面,实体的总计数(如某Feed的总点赞数)对实时性要求较低,允许秒级最终一致。
传统方案要么为了总计数一致性牺牲交互体验(同步写阻塞用户操作),要么为了体验牺牲一致性(异步写导致总计数更新延迟且可能丢失),无法实现两者的合理平衡。
(三)可扩展性与容灾能力不足
1.同步写架构难以水平扩展:当行为量突发增长时,存储层的写压力会直接传导至整个链路,而同步写模式下无法通过简单增加节点分摊压力,系统扩容成本高、响应慢。 2.缺乏容错与回滚机制:一旦存储层出现故障,直接写操作会导致计数丢失或错乱;同时,新功能灰度、故障恢复时缺乏数据回放与补偿能力,运维风险高。 基于上述痛点,本设计通过“异步解耦+写聚合+批量刷写”的核心思路,在保障用户体验的前提下,彻底解决高并发计数的性能与稳定性问题。
二、核心设计思想
核心逻辑是**“解耦与聚合**”:通过三层架构拆分写路径,将"高频细粒度写"转化为“低频批量写",同时平衡用户体验与系统性能,具体设计思想如下:
1.路径解耦:将写路径拆分为“同步事实写”和“异步汇总写”。同步路径仅处理用户维度的即时状态更新(保障交互体验),异步路径处理总计数的汇总与落地(降低系统压力),两者通过事件队列解耦,互不影响。
**2.写聚合优化:**引入中间聚合层,将同一实体、同一指标在时间窗口内的多次增量更新聚合为一次批量更新。通过"时间窗口折叠”减少最终存储的写次数,从根源上解决写放大问题。 a.可靠传输保障:使用Kafka作为事件中间件,实现增量事件的高可靠传输、水平扩展与容灾备份。支持事件回放、灰度发布与故障降级,提升系统灵活性。
3.幂等与原子性保障:全链路设计确保“至少一次投递"+“幂等处理”,避免重复计数;关键环节采用原子操作,防止数据错乱,确保最终计数的准确性。
三、核心架构与流程设计
本方案的整体架构分为“生产端(行为采集)、中间层(事件传输+聚合)、消费端(批量刷写)“三层,各层分工明确、协同工作,以下详细拆解每层设计与完整流程:
(一)整体架构概览
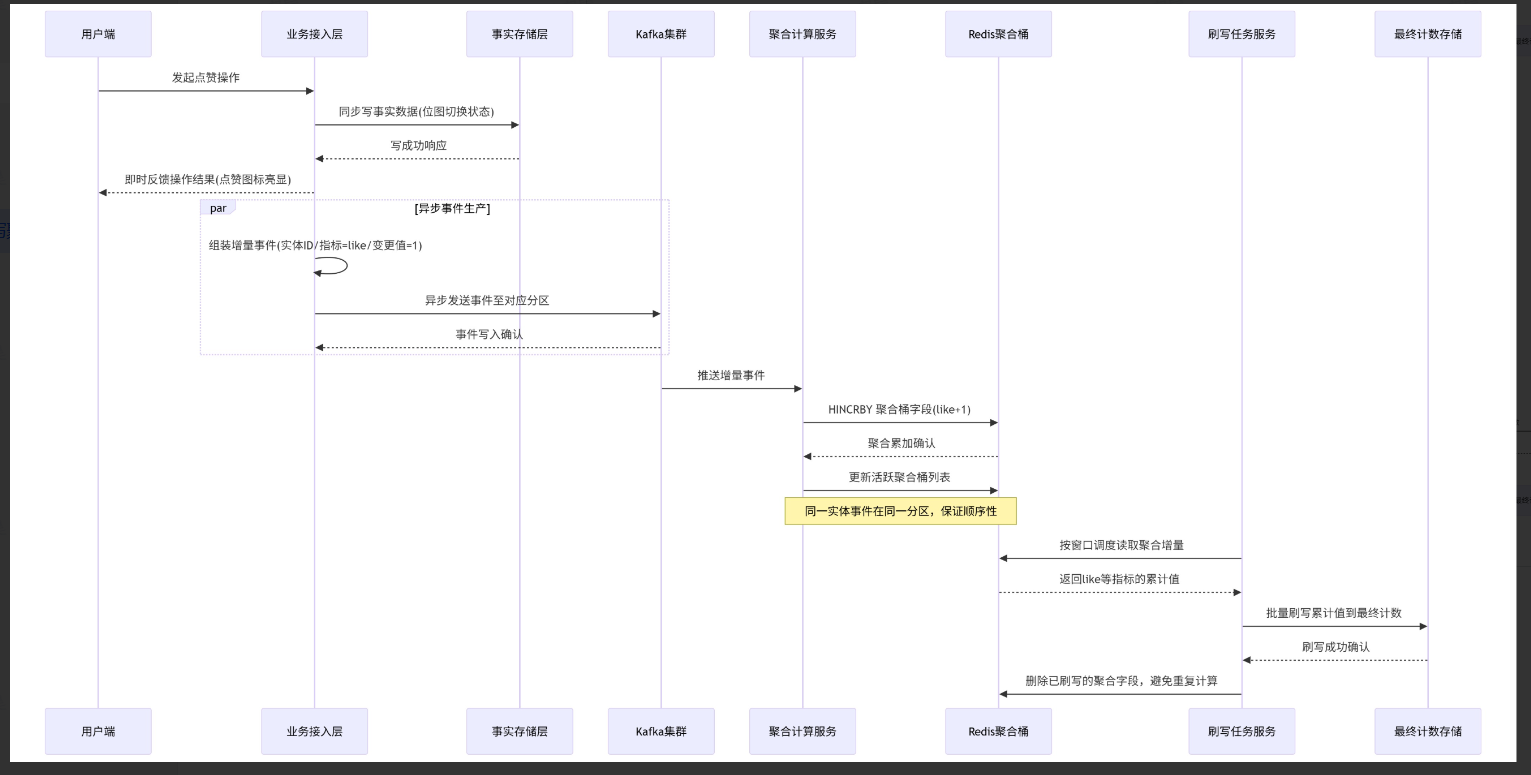
包含Kafka事件队列与Redis聚合层,负责事件可靠传输与增量聚合;
消费端:独立部署的消费服务与刷写任务,负责聚合增量的批量刷写与最终计数落地。
(二)详细流程设计
1.第一步:同步快速路径(保障用户体验) 用户触发行为操作(如点赞、取消点赞)后,首先进入同步路径,核心目标是**"即时响应、状态可见”**,流程如下:
**触发事实写:**同步更新用户维度的事实状态存储(如使用Redis位图、布隆过滤器或数据库行存储)。例如,用户点赞某Feed时,更新"user:123:like:feed”的位图,标记该用户已点赞,确保用户再次访问时能即时看到自己的操作状态。 轻量无阻塞:同步路径仅执行单一、原子的状态更新操作,无复杂计算与锁竞争,确保响应时间控制在毫秒级,不阻塞用户交互。 失败快速反馈:若同步写失败(如缓存超时直接返回用户操作失败,避免用户感知虚假成功”,同时触发重试机制,确保状态一致性。
@PostMapping("/like")
public ResponseEntity<Map<String, Object>> like(@Valid @RequestBody ActionRequest req,
@AuthenticationPrincipal Jwt jwt) {
long uid = jwtService.extractUserId(jwt);
boolean changed = counterService.like(req.getEntityType(), req.getEntityId(), uid);
return ResponseEntity.ok(Map.of(
"changed", changed, // 标识这次操作是否改变状态(避免重复点击)
"liked", counterService.isLiked(req.getEntityType(), req.getEntityId(), uid)
));
}2.第二步:事件生产(异步解耦)
同步路径完成后,异步触发增量事件生产,将计数更新请求剥离到Kafka队列,流程如下:
**构造增量事件:**事件包含核心字段:实体标识(entityId,如Feed ID)、实体类型(entityType,如feed/article) 、指标类型(metric,如like/fav)、变更值(delta,如+1/-1)、时间戳(timestamp)、幂等键(idempotentKey,如"user123_feed456_like_1699999999”)、事实层版本号(version,用于去重)
**异步写入Kafka:**通过异步线程将事件写入Kafka,不阻塞同步路径。生产端配置如下:
可靠性配置:acks=all(确保所有ISR副本写入成功)、开启幂等生产(enable.idempotence=true),避免事件丢失或重复生产;
性能优化:设置合理的linger.ms(如5ms,批量发送)、batch.size (如16KB,批量大小),启用z4/zstd压缩,提升吞吐并降低网络开销;
分区策略:以entityId为分区键(hash(entityId)%分区数),确保同一实体的所有事件进入同一Kafka分区,保障事件顺序,且在消费端集中处理,避免跨分区乱序。
可选outbox模式
Outbox事件驱动模式(用户关系)(本项目中,关注等操作采用Outbox模式,点赞没有):对于核心业务场景,可采用“本地事务+Outbox表”保障事件生产与业务写的一致性。具体为:在同一数据库事务中,更新业务状态(如用户点赞记录)与写入Outbox表(存储事件数据),再通过独立进程读取Outbox表并投递到Kafka,彻底避免“业务成功但事件丢失”的情况。
private boolean toggle(String etype, String eid, long uid, String metric, int idx, boolean add) {
// 固定分片定位:按用户ID映射到 chunk 与分片内 bit 偏移,避免单键膨胀与热点
long chunk = BitmapShard.chunkOf(uid);
// 分片内位偏移
long bit = BitmapShard.bitOf(uid);
String bmKey = CounterKeys.bitmapKey(metric, etype, eid, chunk);
List<String> keys = List.of(bmKey);
List<String> args = List.of(String.valueOf(bit), add ? "add" : "remove");
Long changed = redis.execute(toggleScript, keys, args.toArray());
boolean ok = changed == 1L;
if (ok) {
int delta = add ? 1 : -1;
// 产出计数事件(异步聚合),分区按实体维度保证同实体事件顺序
eventProducer.publish(CounterEvent.of(etype, eid, metric, idx, uid, delta));
// 本地事件:触发缓存失效/旁路更新等快速路径
eventPublisher.publishEvent(CounterEvent.of(etype, eid, metric, idx, uid, delta));
}
return ok;
}3.第三步:事件消费与聚合累加(中间层缓冲)
Kafka消费端不直接写最终计数,而是先将增量事件聚合到中间层(Redis),实现“批量折叠”,流程如下:
**消费端部署:**采用Kafka消费组模式,支持水平扩展(消费组内消费者数量≤分区数),每个消费者独占处理部分分区,确保同一分区的事件顺序消费。 聚合桶设计: 键结构:聚合桶健为 agg:{schema}:(entityType}:{entityId}:{timeslot},其中timeSlot为时间槽(如小时级“2024100114”),用于拆分键空间,避免跨时段集中失效与热点聚集; 存储结构:采用Redis Hash类型,Hash的字段为指标名称(如like/fav),值为该指标在当前时间窗口内的累计增量。例如, agg:V1:feed:456:2024100114 的Hash字段like值为10,代表该Feed在14时的点赞累计增量为10。
**原子累加操作:**消费端接收到事件后,执行Redis HINCRBY命令,将事件中的delta值累加到对应聚合桶的指标字段中。该操作是原子性的,无需加锁,支持高并发写入,且幂等(重复消费同一事件会重复累加delta,但后续刷写逻辑会避免重复落地) **活跃聚合桶管理:**通过Redis Set或SortedSet维护“活跃聚合桶列表”(如active:agg:V1:feed:2024100114),每次更新聚合桶时,将桶键加入该列表,便于刷写任务快速定位需要处理的聚合桶,避免全量扫描。 **聚合桶TTL设置:**为聚合桶设置合理的TTL(如2小时),确保长时间无更新的陈旧桶自动清理,避免Redis内存膨胀;同时,TTL需长于刷写周期,防止刷写前桶被清理。CounterAggregationConsumer.java
@KafkaListener(topics = CounterTopics.EVENTS, groupId = "counter-agg")
public void onMessage(String message, Acknowledgment ack) throws Exception {
CounterEvent evt = objectMapper.readValue(message, CounterEvent.class);
String aggKey = CounterKeys.aggKey(evt.getEntityType(), evt.getEntityId());
String field = String.valueOf(evt.getIdx());
try {
// 将增量持久化到 Redis Hash
redis.opsForHash().increment(aggKey, field, evt.getDelta());
// 成功后提交位点,绑定“已持久化”语义
ack.acknowledge();
} catch (Exception ex) {
// 不提交位点以便重试
}
}搜索系统实现方案
一、为什么要单独做一个搜索模块
随着项目中 知文(knowpost)内容规模的增长,基于数据库的查询方式会逐渐暴露出以下问题: LIKE / MySQL 全文索引 对中文不友好,分词能力弱 难以体现“相关性强弱”,结果排序不自然,不理想
而且很难同时支持: ◦标题权重更高 ◦热度(点赞 / 浏览)加权 ◦高亮命中片段 ◦联想建议(Suggest) ◦深分页(from/size 性能差)  因此,搜索模块的目标不只是“能搜到”,而是:
搜得快、搜得准,并且能随着业务扩展。 核心目标可以概括为四点: 1.用户通过关键词快速找到想要的知文 2.排序符合用户直觉:标题命中 > 热度高 > 更新更近 3.返回结构与 Feed / 我的知文完全一致(复用 FeedItemResponse) 4.内容发布或修改后,能在较短时间内被搜索到(准实时
定制化Redis SDS
https://www.douyin.com/video/7584337972196199732
我们的计数系统不再将点赞数、粉丝数等计数直接落到 MySQL,而是采用 Redis + 自定义 SDS 二进制结构(CountInt) 做统一存储。
对每个用户,仅使用一个 Redis Key 存放一组计数:
- 笔记维度的:阅读数、点赞数、收藏数、评论数、转发数
- 用户维度的:关注数、粉丝数、发布作品数、获得点赞数、获得收藏数
通过紧凑的二进制布局消除字段名和 Redis Hash 元数据开销,相比常规 Hash 结构大幅降低内存占用,并简化 CPU 访问路径。
计数系统被视作对底层“事实表”的高性能近实时视图:业务写入时只更新关系表、作品表等真实数据,而计数由专门的计数模块异步更新 Redis,彻底将计数逻辑从核心交易路径中拆出,降低了主链路的写放大和耦合度。
为了弥补“不落库兜底”带来的风险,我们在 Redis 层开启 RDB 快照 + AOF 持久化,保证重启后计数可以恢复到接近宕机前的状态;同时定期从业务事实表进行 离线聚合对账,对 Redis 中偏离真实值的计数进行自动修正,使整体系统具有**“可恢复、可自愈”**的能力。这样既保留了 Redis 内存计数的极致性能和低延迟,又在可靠性上达到了业务可接受的标准,非常适合点赞数、粉丝数等高频读写计数场景。
一、为什么计数系统单独用 Redis,而不是继续用 MySQL
计数类数据(浏览量、点赞数、收藏数、关注数、粉丝数等)有几个典型特征:
- 读写极高频:一个热门用户/热门作品,计数每秒都在变。
- 更新粒度小且随机:每次只改一个数,还可能集中打在少数热点 Key 上。
- 对“绝对强一致”要求没那么死:
10001和9999对用户来说差别不大,比起“页面加载很慢/操作失败”,用户更在乎“流畅”。
如果计数都落在 MySQL:
- 热点行会频繁
UPDATE,行锁、redo log 压力巨大,很容易撑爆。 - 想做分库分表,计数又和业务数据纠缠在一起,拆分困难。
- 任意一个计数维度新增或变更,都要改表结构,DDL 成本很高。
所以:把计数抽出成一个独立的**“计数服务 + Redis 存储”**,是更合理的架构拆分。
二、为什么采用 Redis SDS + 二进制定制化结构(CountInt)
1. 内存开销更小
如果用普通 Redis 结构(比如 Hash)存一个用户的计数:
1 key = ucnt:123
2 field: followCount, fanCount, workCount, likeCount, favCount
3 value: 100, 50, 20, 999, 12问题:
- 每个 field 都要存一遍 字符串名字("followCount"等),有额外开销。
- Hash 结构内部还有指针、ziplist/hashtable 元数据。
- 用户量一大,会浪费很多内存。
而我们设计的:
1 key = ucnt:123
2 value = 一个连续的二进制块(CountInt):
3 [ offset0: followCount ][ offset1: fanCount ][ offset2: workCount ]
4 [ offset3: likeWorkCount ][ offset4: favWorkCount ]特点:
- 没有字段名,只有值。
- 一个用户只占一个 Key(SDS + 一块连续内存)。
- 对 CPU 来说,访问就是“起始地址 + 类型偏移”,非常友好。
在千万级用户规模下,这种布局能比“Redis Hash + 字符串字段”省下非常可观的内存。
2. CPU 访问模式友好,性能更高
访问方式很简单:
- 想读关注数: base + FOLLOW_OFFSET
- 想改粉丝数: base + FAN_OFFSET
不需要哈希字段查找、不需要解析字符串,减少了一层哈希和对象查找,在高频调用下,对延迟是有实际收益的。
3. 模型清晰: 一个用户 = 一个 CountInt
- 每个用户一个 Key,对应一块 CountInt。
- 所有计数字段的含义由“计数 Schema 中心”统一管理(例如:第1位是关注数、第2位是粉丝数......)。
- 一眼就能对齐“用户维度的计数”,方便压测、迁移和清理。
Key = ucnt:123
+---------------------------+
| SDS |
| |
| readCount: 208 | -----> offset0
| likeCount: 27 | -----> offset1
| favCount: 16 | -----> offset2
| commentCount: 2 | -----> offset3
| shareCount: 10 | -----> offset4
| |
+---------------------------+三、为什么计数“不落库兜底”,而是完全依赖 Redis
这里的设计理念是:
业务事实(比如一条作品、一条关注关系)由数据库持久化; 计数只是**“对事实的聚合视图”**,完全可以由 Redis 维护 + 对账修正。
这么做的好处:
1. 写路径极简
- 业务写关注/作品时,只落 DB 事实表,不需要同时更新一堆计数表。
- 计数更新专门由**“计数服务消费者(Kafka)”**根据事件来操作 Redis。
- 关注主链路只管写事实,计数成为一个独立子系统,职责单一(面向对象六大原则:单一职责原则)。
2. 架构拆分干净
- MySQL 只保存真实业务数据(作品表、关系表等),其 schema 更稳定。
- 计数系统独立演进,不会频繁拖累 DB 的 DDL 与读写负载。
3. 计数抽象为“近实时视图”
- 对用户来说,看到的“粉丝数”“点赞数”只要大体准确即可,允许毫秒级的延迟与极小概率误差。
- 给计数从“必须强一致的账本”降级为“可修复的视图”,你就能换来极大的性能和扩展性。
四、RDB + AOF:在“不落库”的前提下保证可恢复
“完全不落 MySQL”听起来会担心: Redis 崩了计数是不是都没了? 这里必须配合:
1. RDB 快照(RDB)
- 定期(比如 5 分钟/15 分钟)为 Redis 做一份内存快照;
- Redis 重启时可以很快从快照恢复到某个时间点的整体状态。
2. AOF 日志(Append Only File)
- 开启 AOF,策略 appendfsync everysec;
- 每一条计数更新(INCR/DECR/自定义 Lua)都会被持久化写入到 AOF;
- Redis 重启时:先加载 RDB,再重放 AOF,将状态恢复到接近宕机前的时刻;
- 理论上最多丢失 1 秒左右的操作,这个风险你可以结合业务承受能力评估,一般是可以接受的。
3. 多副本 + 主从(后续可扩展)
- 为 Redis 部署主从 + 哨兵或集群;
- 任一实例挂掉,可以自动切换到其他副本继续提供服务。
即使计数不保存在 MySQL,只要 Redis 的 RDB/AOF 机制配置合理, 重启后计数状态仍然能在一个极小误差范围内恢复。
五、定期对账:让 Redis 计数具备“自愈能力”
虽然 RDB + AOF 已经让 Redis 足够可靠,但仍可能存在极端情况(例如硬盘损坏、配置错误、AOF 手工误操作等),这时就要靠对账机制来兜底。
对账的基本思路:
事实表是权威:
粉丝数 → 由 follow/follower 关系表按 user_id 聚合; 点赞数 → 由“位图”按作品或用户聚合; 收藏数 → 同理。
定期任务(每天凌晨/每周):
a. 从 DB 内部聚合出某一批用户的“真实计数”; b. 从 Redis 读出对应用户的当前计数; c. 对比差值,生成“修正操作”,重新写入 Redis。
可以做成:
- 全量批次:一天或一周扫完整库;
- 或滚动窗口:每天对活跃用户、近24小时有行为的用户做对账即可。
通过对账:
- 即使中途某些事件没成功写入 Redis、或者重启时丢失了少量 AOF 日志,也可以在对账时被拉回正确值;
- 系统从“可能永远偏差”变成“短期偏差,长期收敛到正确”。
private boolean toggle(String etype, String eid, long uid, String metric, int idx, boolean add) {
// 固定分片定位:按用户ID映射到 chunk 与分片内 bit 偏移,避免单键膨胀与热点
long chunk = BitmapShard.chunkOf(uid);
// 分片内位偏移
long bit = BitmapShard.bitOf(uid);
String bmKey = CounterKeys.bitmapKey(metric, etype, eid, chunk);
List<String> keys = List.of(bmKey);
List<String> args = List.of(String.valueOf(bit), add ? "add" : "remove");
Long changed = redis.execute(toggleScript, keys, args.toArray());
boolean ok = changed == 1L;
if (ok) {
int delta = add ? 1 : -1;
// 产出计数事件(异步聚合),分区按实体维度保证同实体事件顺序
eventProducer.publish(CounterEvent.of(etype, eid, metric, idx, uid, delta));
// 本地事件:触发缓存失效/旁路更新等快速路径
eventPublisher.publishEvent(CounterEvent.of(etype, eid, metric, idx, uid, delta));
}
return ok;
}产出计数事件、本地事件这两段代码在项目整体里承担的是 “一条异步主链路 + 一条本地快速旁路”。
eventProducer.publish(...) 是把这次点赞/收藏变化封装成计数事件,发到 Kafka。它的作用是把“用户行为”和“计数汇总”解耦,后面的消费者会把增量先写进聚合桶 agg:,再定时折叠到 cnt: 这个计数快照里。也就是说,这一条是项目计数系统的主干异步链路,负责最终一致的总数更新。代码入口在 CounterServiceImpl.java:126,下游是 CounterEventProducer.java:27 和 CounterAggregationConsumer.java:46。
eventPublisher.publishEvent(...) 是在当前应用进程内发布一个 Spring 本地事件,不走 Kafka,不跨进程。它的作用是立刻触发一些“轻量副作用”,比如更新首页 Feed 缓存里的点赞/收藏数,以及同步作者维度的“获赞/获收藏”计数。下游监听器是 FeedCacheInvalidationListener.java:65。也就是说,这一条是快速响应链路,目的是让页面和局部缓存尽快跟上变化,不必等 Kafka 聚合刷盘。
为什么要同时存在:因为只走 Kafka 会有秒级延迟,只走本地事件又无法支撑可靠的全局异步聚合。所以项目把两者结合起来:Kafka 负责可靠异步汇总,本地事件负责快速缓存联动。
六、计数的相关思考
用户点一次赞的完整时序
用户
|
| 1. POST /api/v1/action/like
v
ActionController
|
| 2. 解析当前登录用户 userId
| 3. 调 counterService.like("knowpost", postId, userId)
v
CounterServiceImpl.like(...)
|
| 4. 进入 toggle(...)
| 5. 根据 userId 计算 chunk 和 bit
| chunk = userId / 32768
| bit = userId % 32768
|
| 6. 生成位图分片 key:
| bm:like:knowpost:{postId}:{chunk}
|
| 7. 执行 Lua:原子判断 + 原子置位
| - 原来没点赞: 置 1,返回 changed=1
| - 原来已点赞: 不重复置位,返回 changed=0
v
Redis Bitmap(事实层)
|
| 8. 如果 changed=1,说明这次点赞真实生效
|
|---> CounterEventProducer.publish(...)
| |
| | 9. 组装 CounterEvent:
| | entityType=knowpost
| | entityId=postId
| | metric=like
| | idx=1
| | uid=userId
| | delta=+1
| v
| Kafka topic: counter-events
|
|---> eventPublisher.publishEvent(...)
|
| 10. 发布本地 Spring 事件
v
FeedCacheInvalidationListener
|
| 11. 旁路更新:
| - 更新 Feed 页缓存中的点赞数
| - 给作者的 likesReceived +1
v
本地缓存 / 用户维度计数
Kafka
|
| 12. CounterAggregationConsumer.onMessage(...)
v
CounterAggregationConsumer
|
| 13. 写入聚合桶 Hash:
| agg:v1:knowpost:{postId}
| field = 1
| value += 1
|
| 14. 入桶成功后手动 ack
v
Redis Hash(聚合层)
定时任务每 1 秒
|
| 15. flush()
v
CounterAggregationConsumer.flush()
|
| 16. 扫描 agg:v1:* 聚合桶
| 17. 找到 agg:v1:knowpost:{postId}
| 18. 读到 field=1, delta=+1
|
| 19. 用 Lua 原子折叠到 SDS:
| cnt:v1:knowpost:{postId}
| 第 1 段 likeCount += 1
|
| 20. 成功后删除 agg 对应 field
v
Redis SDS(快照层)
后续查询
|
| 21. GET /api/v1/counter/knowpost/{postId}?metrics=like,fav
| 或 Feed/详情页内部读计数
v
CounterServiceImpl.getCounts(...)
|
| 22. 优先读 cnt:v1:knowpost:{postId}
| 23. 按固定偏移解析 like/fav
v
返回当前点赞数大佬总结
https://k74o3vlpnz.feishu.cn/wiki/KpeqwVTGPiisw8kqruTcIzkTn5y
七、Kafka在项目中以及在点赞计数中的作用
1. 解耦:点赞请求不直接改最终总数,而是先发事件 位置:CounterServiceImpl.java:121
Long changed = redis.execute(toggleScript, keys, args.toArray());
boolean ok = changed == 1L;
if (ok) {
int delta = add ? 1 : -1;
// 产出计数事件(异步聚合),分区按实体维度保证同实体事件顺序
eventProducer.publish(CounterEvent.of(etype, eid, metric, idx, uid, delta));
// 本地事件:触发缓存失效/旁路更新等快速路径
eventPublisher.publishEvent(CounterEvent.of(etype, eid, metric, idx, uid, delta));
}- 同步请求里只做“位图事实更新”
- 真正的总数更新不在这里同步做
- 而是通过 eventProducer.publish(...) 把变化发出去,交给后面的异步链路处理
2. 削峰:先进入 Kafka,而不是直接打快照 位置:CounterEventProducer.java:27
public void publish(CounterEvent event) {
try {
String payload = objectMapper.writeValueAsString(event);
kafka.send(CounterTopics.EVENTS, payload); // 异步写入计数事件主题(幂等生产已在配置启用)
} catch (JsonProcessingException e) {- 点赞产生的变化不会直接去改 cnt:*
- 而是先发到 Kafka counter-events
- Kafka 在这里就是缓冲层,起到削峰作用
3. 保证最终一致:消费者先写聚合桶,再定时刷到 cnt:* 先看消费入桶,位置:CounterAggregationConsumer.java:46
@KafkaListener(topics = CounterTopics.EVENTS, groupId = "counter-agg")
public void onMessage(String message, Acknowledgment ack) throws Exception {
CounterEvent evt = objectMapper.readValue(message, CounterEvent.class);
String aggKey = CounterKeys.aggKey(evt.getEntityType(), evt.getEntityId());
String field = String.valueOf(evt.getIdx());
try {
// 将增量持久化到 Redis Hash
redis.opsForHash().increment(aggKey, field, evt.getDelta());
// 成功后提交位点,绑定“已持久化”语义
ack.acknowledge();
} catch (Exception ex) {
// 不提交位点以便重试
}
}再看定时刷写,位置:CounterAggregationConsumer.java:65
@Scheduled(fixedDelay = 1000L)
public void flush() {
Set<String> keys = redis.keys("agg:" + CounterSchema.SCHEMA_ID + ":*");
if (keys.isEmpty()) {
return;
}
for (String aggKey : keys) {
Map<Object, Object> entries = redis.opsForHash().entries(aggKey);
if (entries.isEmpty()) {
continue;
}
String[] parts = aggKey.split(":", 4); // agg:schema:etype:eid
if (parts.length < 4) {
continue;
}
String cntKey = CounterKeys.sdsKey(parts[2], parts[3]);
for (Map.Entry<Object, Object> e : entries.entrySet()) {
String field = String.valueOf(e.getKey());
long delta;
try {
delta = Long.parseLong(String.valueOf(e.getValue()));
} catch (NumberFormatException nfe) {
continue;
}
if (delta == 0) continue;
int idx;
try {
idx = Integer.parseInt(field);
} catch (NumberFormatException nfe) {
continue;
}
try {
redis.execute(incrScript, List.of(cntKey),
String.valueOf(CounterSchema.SCHEMA_LEN),
String.valueOf(CounterSchema.FIELD_SIZE),
String.valueOf(idx),
String.valueOf(delta));
// 成功后删除该字段,避免重复加算
redis.opsForHash().delete(aggKey, field);
} catch (Exception ex) {
// 留存字段,下一轮重试
}
}- 消费消息失败:Kafka 位点不提交,下次还能重新消费
- 刷写快照失败:聚合桶字段不删,下次定时任务还能继续刷
一句话总结
- CounterServiceImpl:把同步写请求拆成事件
- CounterEventProducer:把事件送进 Kafka
- CounterAggregationConsumer.onMessage:把事件落到 agg:*
- CounterAggregationConsumer.flush:把 agg:* 折叠进 cnt:*
面试:
定制化Redis SDS是什么,为什么要存在这里?--腾讯CSIG输入法一面
借用了 Redis String 底层是 SDS(二进制安全字符串)这个特性,把多个计数值按固定字节布局塞进一个 Redis String 里。
在这个项目里,它本质上就是一个 紧凑的二进制计数快照:
- 内容计数存在 cnt:{schema}:{etype}:
- 用户计数存在 ucnt:
- 每个指标占固定 4 字节,按固定偏移读写,比如点赞、收藏、粉丝数、发文数都放在不同“槽位”里
为什么要这么做:
- 读特别快 一次 GET 就能拿到整组计数,不用多个 key、多次网络往返。
- 更省内存 比起 Redis Hash 这种字段名+值的结构,固定二进制布局更紧凑。
- 更适合高并发计数场景 这个项目的点赞、收藏、粉丝、发文数都是高频读,SDS 适合做“汇总快照层”。
- 方便和位图事实层配合 项目里真实状态存在位图里,SDS 只负责低延迟读取;如果 SDS 丢了或异常,还能根据位图重建。
项目自己设计了一种“把多个计数压缩进一个 Redis 字符串”的存储格式,所以叫“定制化 Redis SDS”。
面试官:我看你将帖子的点赞数、收藏数这种计数的业务放入redis当中,如果redis断电,数据丢失了怎么办呢?*
回答:好的,面试官。**首先针对于这种读多写多,且对于数据的强一致性的要求没有那么高的场景下,比如计数业务,我会将数据存入redis缓存当中,在高并发的场景下,尽可能的提升性能。其次,再谈到redis断电,宕机等意外情况发导致数据丢失的情况。首先呢,就是需要开启Redis自带的RDB快照和AOF,比如说,每五分钟对当前redis中的数据做一份内存快照,同时开启AOF,策略:**appendfsync everysec 尽可能的保证数据恢复到断电、宕机之前的状态。同时,定期从事务表进行离线聚合对账,对redis中的偏离数据进行自动修正。其次,在项目中我还增加了重建机制。当数据出现丢失,或者结构出现异常,就会进行重建。为了防止重建风暴我在重建之时还加了三层防护机制,“指数退避”,“令牌桶限流”、“分布式锁”。使得其在高并发状态下不会直接打垮redis。在经过上述三道防线之后,会从我设计的Redis 分片Bitmap 里通过管道批量计算真实计数,重新构建我定制化的 SDS紧凑计数结构,写回Redis。
RAG知识问答系统
基于 RAG 的单篇知文知识问答实现与原理
在【知光】项目中,我们希望用户在阅读一篇知文时,能够直接就这篇内容发问,并获得结合原文上下文的智能回答。为此,后端实现了一套基于 RAG(Retrieval-Augmented Generation,检索增强生成)的单篇知识问答方案。
下面从整体流程、索引构建、向量检索、提示词构造、流式输出、权限控制以及性能优化几个方面,系统地介绍这套方案是怎么落地的。
一、整体流程:从用户问题到流式回答
整体流程可以概括为一句话:
用户调用问答接口 → 后端确保该知文已构建向量索引 → 在向量库中检索相关片段 → 拼接为上下文构造 Prompt → 调用聊天模型生成回答,并以 SSE 流式返回。
再详细一点的流程是:
入口请求 前端调用 GET /api/v1/knowposts/{id}/qa/stream,携带问题 question,后端返回 text/event-stream 类型的
Flux<String>,前端用 EventSource 消费。索引兜底 RagQueryService.streamAnswerFlux 会先调用 RagIndexService.ensureIndexed(postId),确保当前知文已被切块并写入向量库。
向量检索 使用 Spring AI 的 VectorStore.similaritySearch 对问题进行向量化,在 ES 向量索引中检索相似文档,并按 metadata.postId 过滤,只保留当前知文的分块。
构造 Prompt 将检索到的若干文本块拼成上下文,加上系统指令与用户问题,组成一条结构化的对话 Prompt。
调用大模型并流式返回 使用 ChatClient.stream() + DeepSeek 模型生成回答,后端以 SSE 形式逐片段推送,前端能看到实时滚动的回答文本。
二、入口与路由:基于 WebFlux 的 SSE 流式问答
1. 控制器设计
• 控制器类:KnowPostRagController.java • 路由:GET /api/v1/knowposts/{id}/qa/stream • 返回值:Flux<String>,由 Spring WebFlux 自动封装为 text/event-stream(SSE)
相比过去常见的 SseEmitter 方案,基于 WebFlux 的写法有两点优势:
• 天然支持背压与响应式流:不用手动管理连接生命周期,Flux 终止即连接结束。 • 代码风格统一:与后端已有的响应式接口保持一致,便于扩展和链式操作。
前端只需要通过原生 EventSource 或对应封装,就能顺畅消费这条流式问答。
/**
* 单篇知文 RAG 问答(WebFlux + Flux 流式输出)。
* 示例:GET /api/v1/knowposts/{id}/qa/stream?question=...&topK=5&maxTokens=1024
*/
@GetMapping(value = "/{id}/qa/stream", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> qaStream(@PathVariable("id") long id,
@RequestParam("question") String question,
@RequestParam(value = "topK", defaultValue = "5") int topK,
@RequestParam(value = "maxTokens", defaultValue = "1024") int maxTokens) {
return ragQueryService.streamAnswerFlux(id, question, topK, maxTokens);
}2. 安全配置
在 SecurityConfig.java 中:
• 对知文详情与本次 RAG 流式问答接口放行匿名访问; • 真正的可见性与状态控制,不靠权限拦截,而是由业务逻辑决定(例如:仅索引已发布、公开的内容)。
这样既保证了前台阅读和问答体验的顺畅,又不破坏安全边界。
@Bean
public SecurityFilterChain securityFilterChain(HttpSecurity http) throws Exception {
http
.csrf(AbstractHttpConfigurer::disable)
.cors(Customizer.withDefaults())
.sessionManagement(session -> session.sessionCreationPolicy(SessionCreationPolicy.STATELESS))
.authorizeHttpRequests(auth -> auth
.requestMatchers("/actuator/health", "/actuator/info").permitAll()
// 公开内容:首页 Feed 不需要登录
.requestMatchers("/api/v1/knowposts/feed").permitAll()
// 知文详情(公开已发布内容,非公开由服务层校验)
.requestMatchers(org.springframework.http.HttpMethod.GET, "/api/v1/knowposts/detail/*").permitAll()
// 知文详情页 RAG 问答(SSE 流式输出)允许匿名访问
.requestMatchers(org.springframework.http.HttpMethod.GET, "/api/v1/knowposts/*/qa/stream").permitAll()
.requestMatchers(
"/api/v1/auth/send-code",
"/api/v1/auth/register",
"/api/v1/auth/login",
"/api/v1/auth/token/refresh",
"/api/v1/auth/logout",
"/api/v1/auth/password/reset"
).permitAll()
.anyRequest().authenticated()
)
.oauth2ResourceServer(oauth -> oauth.jwt(Customizer.withDefaults()));
return http.build();
}三、索引构建:从 Markdown 正文到语义分块
RAG 的核心前提是:有一份干净、可检索的向量化文档索引。 这一部分由 RagIndexService 负责。
1. 触发时机
RagIndexService.ensureIndexed(postId) 会在两个阶段触发:
- 预索引阶段:知文发布/确认内容时,后台主动执行索引构建,减少首次问答的冷启动。
KnowPostServiceImpl.java
/**
* 确认内容上传(写入 objectKey、etag、大小、校验和,并生成公共 URL)。
*/
@Transactional
public void confirmContent(long creatorId, long id, String objectKey, String etag, Long size, String sha256) {
// 缓存双删
invalidateCache(id);
KnowPost post = KnowPost.builder()
.id(id)
.creatorId(creatorId)
.contentObjectKey(objectKey)
.contentEtag(etag)
.contentSize(size)
.contentSha256(sha256)
.contentUrl(publicUrl(objectKey))
.updateTime(Instant.now())
.build();
int updated = mapper.updateContent(post);
if (updated == 0) {
throw new BusinessException(ErrorCode.BAD_REQUEST, "草稿不存在或无权限");
}
invalidateCache(id);
// 触发一次预索引(草稿阶段可能因可见性/状态被跳过)
try {
ragIndexService.ensureIndexed(id);
} catch (Exception e) {
log.warn("Pre-index after content confirm failed, post {}: {}", id, e.getMessage());
}
}
/**
* 发布草稿,设置状态与发布时间。
*/
@Transactional
public void publish(long creatorId, long id) {
int updated = mapper.publish(id, creatorId);
if (updated == 0) {
throw new BusinessException(ErrorCode.BAD_REQUEST, "草稿不存在或无权限");
}
try {
userCounterService.incrementPosts(creatorId, 1);
} catch (Exception ignored) {}
// 发布成功后触发一次预索引,减少首次问答冷启动
try {
ragIndexService.ensureIndexed(id);
} catch (Exception e) {
log.warn("Pre-index after publish failed, post {}: {}", id, e.getMessage());
}
}- 问答兜底阶段:当用户调用问答接口时,再次执行 ensureIndexed(postId),若此前因各种原因未成功索引,可在这里兜底重建。
RagQueryService.java
public Flux<String> streamAnswerFlux(long postId, String question, int topK, int maxTokens) {
// 轻量保障:如索引不存在或指纹未变更则跳过,否则重建
indexService.ensureIndexed(postId);
// 检索上下文:先宽召回,再按 postId 做服务端过滤
List<String> contexts = searchContexts(String.valueOf(postId), question, Math.max(1, topK));
// 组装上下文文本,分隔符用于提示词中分块标识
String context = String.join("\n\n---\n\n", contexts);
// 系统提示:限定只依据提供的上下文作答,无法确定需明确说明
String system = "你是中文知识助手。只能依据提供的知文上下文回答;无法确定的请说明不确定。";
// 用户消息:包含问题和召回到的上下文
String user = "问题:" + question + "\n\n上下文如下(可能不完整):\n" + context + "\n\n请基于以上上下文作答。";
return chatClient
.prompt() // 构建对话
.system(system)
.user(user)
.options(DeepSeekChatOptions.builder()
.model("deepseek-chat") // 指定 DeepSeek 模型
.temperature(0.2) // 低温度:更稳健、少发散
.maxTokens(maxTokens) // 控制最大输出长度
.build())
.stream() // 以流式(SSE)返回模型输出
.content(); // 转换为 Flux<String>
}2. 原文获取与权限校验
索引构建的源头是:
• 通过 KnowPostMapper.xml 查询 KnowPostDetailRow,拿到 contentUrl 等字段; • 使用 RestTemplate 请求 contentUrl 获取 Markdown 正文; • 只在 status=published 且 visible=public 的情况下才进行索引,避免未公开内容被检索。
如果 contentUrl 为空,则跳过并告警,不做索引。
RagIndexService.java
// 抓取 Markdown 正文
String text = fetchContent(row.getContentUrl());
if (!StringUtils.hasText(text)) {
log.warn("Post {} content empty", postId);
return 0;
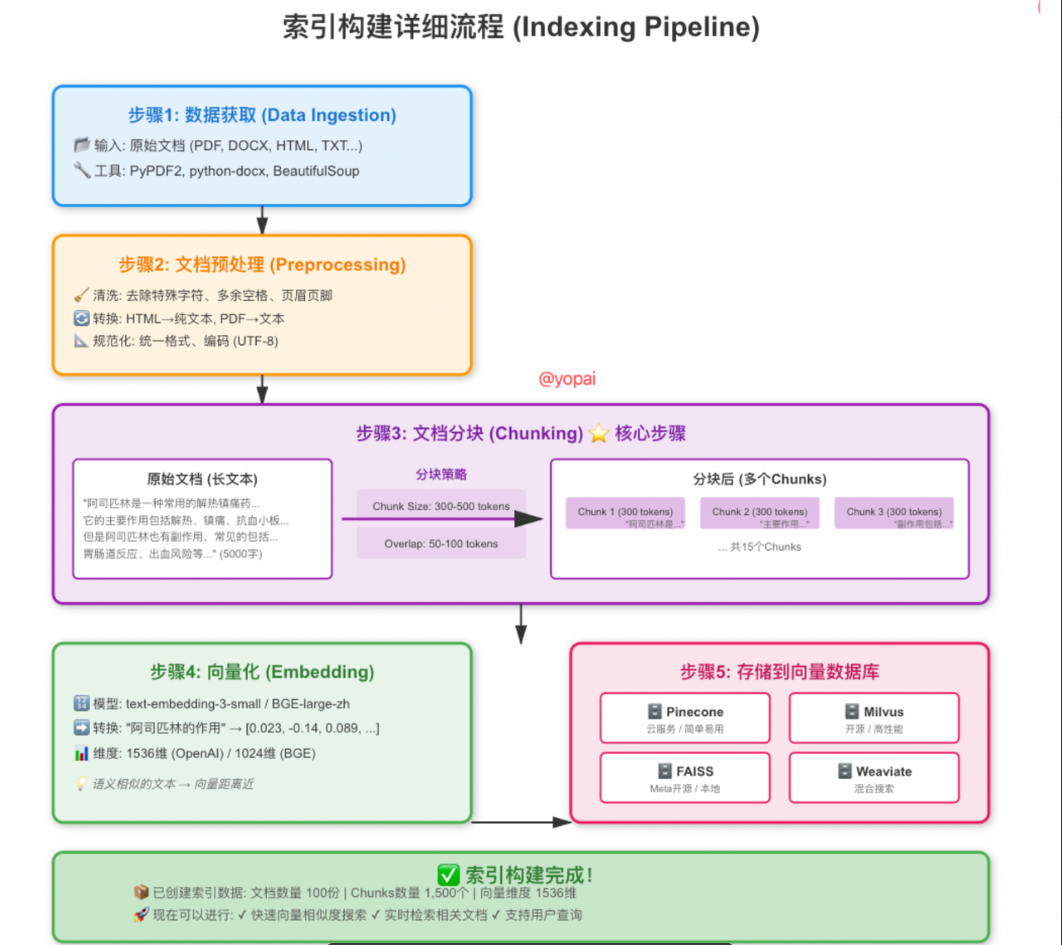
}3. 分块策略:按标题切段 + 字符重叠
为了让向量检索更贴近人类阅读结构,索引分块采用两级策略:
- 按 Markdown 标题切段: ◦ 使用 chunkMarkdown 按行扫描正文,每遇到以 # 开头的标题行,即视为新段落。 ◦ 每个段落通常对应文章中的一个小节,尽量避免跨节段的语义污染。
- 按长度细分 + 重叠: ◦ 对每个段落再用 getChunks 切割为不超过约 800 字符的小块; ◦ 不同块之间采用约 100 字符的重叠,保证句子不被硬截断,提升语义连续性和召回质量。
简化理解:
按“节”切成几大块,再按“长度”切成模型友好的小块,并通过重叠来保证上下文连贯。
RagIndexService.java
/**
* 按 Markdown 标题切段,再交由固定长度切片策略处理。
*/
private List<String> chunkMarkdown(String text) {
List<String> paras = new ArrayList<>();
String[] lines = text.split("\r?\n");
StringBuilder buf = new StringBuilder();
for (String line : lines) {
boolean isHeader = line.startsWith("#");
if (isHeader && !buf.isEmpty()) { // 遇到新的标题,收束上一段
paras.add(buf.toString());
buf.setLength(0);
}
buf.append(line).append('\n');
}
if (!buf.isEmpty()) paras.add(buf.toString());
return getChunks(paras);
}
/**
* 固定长度切片(每片 ≤ 800 字符),切片间 100 字符重叠:
* - 兼顾检索召回与上下文连续性
*/
private static List<String> getChunks(List<String> paras) {
List<String> chunks = new ArrayList<>();
for (String p : paras) {
if (p.length() <= 800) {
chunks.add(p);
} else {
int start = 0;
while (start < p.length()) {
int end = Math.min(start + 800, p.length());
chunks.add(p.substring(start, end));
if (end >= p.length()) break;
start = Math.max(end - 100, start + 1); // 重叠 100 字符以保留语义连续
}
}
}
return chunks;
}举个例子:
原文:
阿司匹林是一种常用的解热镇痛药。它的主要作用包括:
1. 解热:降低发烧体温
2. 镇痛:缓解轻到中度疼痛
3. 抗血小板:预防血栓形成
但是,阿司匹林也有副作用。常见的副作用包括:
胃肠道反应:胃痛、恶心 出血风险:特别是长期服用分块后:
Chunk 1: "阿司匹林是一种常用的解热镇痛药。它的主要作用包括:
1. 解热:降低发烧体温
2. 镇痛:缓解轻到中度疼痛
3. 抗血小板:预防血栓形成"
Chunk 2: "阿司匹林的主要作用包括预防血栓形成。但是,阿司匹林也有副作用。
常见的副作用包括:
1. 胃肠道反应:胃痛、恶心
2. 出血风险:特别是长期服用"注意Chunk 2 有重叠,这样即使用户搜“副作用”,也能同时看到“作用”相关的上下文。
4. 元数据与幂等控制
每个最终切片会被包装成一个 Document 写入向量库,其关键字段包括:
• text:该块的纯文本内容• metadata:◦ postId◦ chunkId(如 postId#序号)◦ position(块在正文中的顺序)◦ title(所在小节标题)◦ contentUrl◦ contentEtag / contentSha256(内容指纹)
为保证幂等与更新正确性:
- 指纹检测 ◦ 按
metadata.postId查询 ES 中已有文档; ◦ 若其中的contentSha256或contentEtag与当前内容一致,则认为正文未变,直接跳过重建。 - 变更重建 ◦ 若指纹不一致,则先对该
postId执行delete-by-query删除旧分块; ◦ 然后重新执行分块与VectorStore.add(docs)写入。
这样可以避免重复写入和旧版本脏数据,确保向量库始终与最新内容对齐。
RagIndexService.java
/**
* 指纹判断是否需要重建:
* - 以 postId 查询任意一条已索引文档的 metadata
* - 优先比较 SHA256,其次比较 ETag;一致则视为无需重建
*/
private boolean isUpToDate(long postId, String currentSha, String currentEtag) {
try {
if (!StringUtils.hasText(esProps.getIndex())) {
// 未配置索引名则无法判断,直接视为需要重建
return false;
}
SearchResponse<Map> resp = es.search(s -> s
.index(esProps.getIndex())
.size(1)
.query(q -> q.term(t -> t
.field("metadata.postId")
.value(v -> v.stringValue(String.valueOf(postId))))),
Map.class);
List<Hit<Map>> hits = resp.hits().hits();
if (hits == null || hits.isEmpty()) return false;
Map source = hits.getFirst().source();
if (source == null) return false;
Object metaObj = source.get("metadata");
if (!(metaObj instanceof Map<?, ?> meta)) return false;
String indexedSha = asString(meta.get("contentSha256"));
String indexedEtag = asString(meta.get("contentEtag"));
if (StringUtils.hasText(currentSha) && StringUtils.hasText(indexedSha)) {
return Objects.equals(currentSha, indexedSha);
}
if (StringUtils.hasText(currentEtag) && StringUtils.hasText(indexedEtag)) {
return Objects.equals(currentEtag, indexedEtag);
}
return false;
} catch (Exception e) {
log.warn("Fingerprint check failed for post {}: {}", postId, e.getMessage());
return false;
}
}四、向量存储:Elasticsearch + Spring AI VectorStore
1. 为什么需要向量化?
想象你在找"感冒药",但文档里写的是"抗感冒药物"、"治疗感冒的药品"等各种说法。如果只靠关键词匹配,就找不到了。
但是!如果用向量化:``
"感冒药" → [0.1, 0.3, 0.5, ...]
"抗感冒药物" → [0.12, 0.29, 0.51, ...] # 向量很接近!
"汽车" → [0.8, 0.1, 0.2, ...] # 向量差很远向量之间可以计算相似度(余弦相似度),数值越接近1越相似;
2. ES 向量索引配置
在 application.yml 中:
• spring.ai.vectorstore.elasticsearch.index-name: zhiguang-ai-index• spring.ai.vectorstore.elasticsearch.initialize-schema: true → 当索引不存在时,Spring AI 会按预设 schema 自动创建。
嵌入模型配置:
• spring.ai.openai.embedding.options.model: text-embedding-v4 这是一个兼容 OpenAI 协议的嵌入模型,向量维度为 1536,相似度量为 cosine,底层索引类型使用 HNSW(高效近似最近邻检索)。
3. 客户端与属性封装
• ES 客户端由 ElasticsearchConfig.java + EsProperties.java 提供 ElasticsearchClient; • 向量存储使用 Spring AI 自带的 Elasticsearch VectorStore 实现,索引名通过 EsProperties.index 读取自配置。
开发视角下,我们只需要关心 VectorStore 提供的接口(如 add,similaritySearch),具体向量字段名、mapping、HNSW 参数等,都由 Spring AI 和 ES 负责。
五、检索与提示词:如何把"相关内容"喂给大模型
1. 检索逻辑:扩大召回 + 按 postId 过滤
在 RagQueryService.streamAnswerFlux 中:
- 调用 ensureIndexed(postId) 确保索引存在;
- 使用 VectorStore.similaritySearch 对用户问题进行相似度检索;
- 为了避免漏召回,设置 fetchK = max(topK * 3, 20),即: ◦ 比用户期望用来回答的问题块数多拉几倍回来;
- 然后在应用层按 metadata.postId 过滤,只保留当前知文的分块;
- 最后从过滤结果前 topK 作为真正参与回答的上下文。
2. 提示词构造:系统指令 + 问题 + 上下文
构造给大模型的 Prompt 时,大致采用如下结构:
• system 消息: 指定角色和约束,例如: ◦ 你是一名中文知识助手; ◦ 只依据提供的上下文回答问题; ◦ 如果上下文中没有给出答案,请直接说明“不确定”或“没有相关信息”,而不是瞎编。
• user 消息: 将用户问题与检索到的若干上下文块拼接,中间用分隔线区分,例如: ◦ 上半部分是用户提问; ◦ 下半部分是“参考资料”,由多个 chunk 的文本组成。
这样做的目的是最大限度降低幻觉:
模型不再“硬想”,而是在“看完参考资料”后回答。
RagQueryService.java
/**
* 使用 WebFlux 返回回答内容的流。
*/
public Flux<String> streamAnswerFlux(long postId, String question, int topK, int maxTokens) {
// 轻量保障:如索引不存在或指纹未变更则跳过,否则重建
indexService.ensureIndexed(postId);
// 检索上下文:先宽召回,再按 postId 做服务端过滤
List<String> contexts = searchContexts(String.valueOf(postId), question, Math.max(1, topK));
// 组装上下文文本,分隔符用于提示词中分块标识
String context = String.join("\n\n---\n\n", contexts);
// 系统提示:限定只依据提供的上下文作答,无法确定需明确说明
String system = "你是中文知识助手。只能依据提供的知文上下文回答;无法确定的请说明不确定。";
// 用户消息:包含问题和召回到的上下文
String user = "问题:" + question + "\n\n上下文如下(可能不完整):\n" + context + "\n\n请基于以上上下文作答。";
return chatClient
.prompt() // 构建对话
.system(system)
.user(user)
.options(DeepSeekChatOptions.builder()
.model("deepseek-chat") // 指定 DeepSeek 模型
.temperature(0.2) // 低温度:更稳健、少发散
.maxTokens(maxTokens) // 控制最大输出长度
.build())
.stream() // 以流式(SSE)返回模型输出
.content(); // 转换为 Flux<String>
}六、模型调用与流式输出:DeepSeek + ChatClient.stream
3. 模型配置与选择
在 LlmConfig.java 中:
• 通过 @Qualifier 将 ChatClient 绑定到 deepSeekChatModel; • 避免与可能存在的 openAiChatModel 冲突; • 模型选项通过 DeepSeekChatOptions 设置,如: ◦ model = deepseek-chat ◦ temperature(控制随机性) ◦ maxTokens(回答长度,由入参控制)
4. 流式生成与 SSE 输出
在 RagQueryService 中,调用:
chatClient.stream()得到一个 Flux<String>,每个元素都是模型新生成的一小段文本。控制器直接返回这个 Flux<String>,Spring WebFlux 会自动:
• 将每个元素包装为 SSE 事件; • 按顺序推送给前端; • 流结束时自动关闭连接。
从用户视角看,就是一个逐字/逐句滚动出现的回答体验。
七、权限、安全与错误处理
5. 权限与可见性
• 索引侧:RagIndexService 只会为 published 且 public 的知文构建索引; • 检索侧:检索结果只按 metadata.postId 过滤当前知文,不会跨帖泄露内容; • 安全配置:虽然问答接口对匿名用户开放,但真正能被索引和检索到的内容,本身就是已经公开的。
6. 错误处理与兜底策略
• 内容缺失: 若 contentUrl 为空 → 不索引,记录告警。问答时检索不到内容,模型会在“无上下文”的 system 约束下给出“不确定”等回答。
• 索引失败: VectorStore.add 抛异常时,会记录日志并返回 0。问答阶段依然会去检索,只是上下文可能为空。
• 模型异常: 同项目中 KnowPostDescriptionServiceImpl.java 一样,统一封装为 BusinessException 等业务异常。 流式回答时,若中途出错,则会结束 Flux,前端可根据断流做提示。
八、性能与优化
当前方案在性能上已经做了多处考量:
• 合理分块:每块 ~800 字符 + 100 字符重叠,既保证语义完整,又避免单块过大撑爆上下文窗口。 • 指纹跳过:通过 contentSha256 / contentEtag 跳过未变更内容,降低重复写入成本。 • 需等删除:变更前先 delete-by-query,保持单一版本,避免检索出重复块。 • 预索引:发布/确认内容时提前构建索引,减少用户首次提问的等待时间。未来也可以改为异步入队,由消费端批量处理。
发布系统模块
1. 讲述一下你项目里的发布流程,从用户点击“发布”到发布成功都发生了什么?
这个项目里的发布不是一次接口全做完,而是一个渐进式发布流程。
第一步,用户先创建草稿,后端生成一条草稿记录,状态是 draft。 第二步,正文内容不是直接传给后端,而是后端先生成一个临时上传凭证,前端拿着这个凭证直接把正文传到对象存储。传完以后,再调用确认接口,把正文的存储地址、对象键、大小、校验值这些信息回传给后端,后端把这些元数据落库。 第三步,用户再补充标题、标签、可见范围、封面图这些元数据。 第四步,用户点击发布,后端把这条草稿状态改成 published,写入发布时间。 第五步,发布成功后会做一些后置动作,比如作者发文数加一,以及触发一次内容预索引,减少后面搜索和问答的冷启动。
先建草稿,再传正文,再补元数据,最后正式发布。正文和元数据是分阶段提交的。
这样设计的好处是:
- 大文件上传和业务提交解耦
- 发布流程更稳定
- 中间失败也容易恢复,不会一把全废掉
2. 你简历上的渐进式发布流程是什么意思?
业务上的分步发布。
意思是用户发一篇内容,不是一次请求把正文、图片、标签、状态全部写进去,而是拆成几个阶段:
- 先创建草稿
- 再上传正文和资源
- 再补齐元数据
- 最后再点击发布,把状态切成已发布
这样做的原因主要有三个:
第一,上传正文和图片本身可能比较重,如果跟最终发布绑死在一个请求里,失败成本很高。 第二,草稿态能让用户反复编辑,不影响线上内容。 第三,后续像预索引、缓存刷新、计数更新这些动作,也更容易挂在“正式发布”这个明确节点上。
前端直传 OSS 和先传给后端再传到 OSS 有什么差别?优势在哪?
两种方式本质区别在于:文件流到底经过谁。
第一种,先传给后端,再由后端上传到 OSS。 这种方式下,文件流是:前端 -> 后端 -> OSS。 优点是后端控制力强,适合小文件、头像这类简单场景。 缺点是后端会变成中转站,占带宽、占内存、占线程。
第二种,前端直传 OSS。 这种方式下,文件流是:前端 -> OSS。 后端只负责提前签发一个临时上传凭证,告诉前端“你可以往哪个地址、在多久内、用什么方式上传”。 优点是:
- 后端压力小
- 上传速度更高
- 大文件场景更合适
- 前后端和存储职责更清晰
在这个项目里,正文上传走的就是后端签发临时凭证 + 前端直传 OSS。 头像上传走的是后端中转。
小文件、强管控场景可以走后端中转;大文件、正文、图片资源这类高频上传场景,更适合前端直传
4. 预签名是什么?解释一下
预签名可以理解成:后端提前签发的一张“临时通行证”。
它本身不是账号密码,也不是长期权限,而是一个带时间限制、带操作限制、带目标限制的临时上传地址。
比如在这个项目里,后端会告诉前端:
ping curl netstat ssh telnet ifconfig:网络通讯相关、
前端拿到这个地址以后,就可以直接把文件传到 OSS。 一旦过期,或者参数不匹配,这个地址就失效了。
不把 OSS 的长期密钥暴露给前端,但又允许前端在受控范围内直接上传。
5. 为什么内容正文要存到 OSS?存数据库不行吗?
不是说数据库绝对不能存正文,而是从这个项目的场景看,存 OSS 更合适。
原因主要有四个:
第一,正文内容相对比较大,而且会频繁编辑。 如果都塞数据库,大字段会让数据库变重,**影响行数据读写效率,也不利于后续扩容**。
第二,数据库更适合存结构化数据和业务元数据。 比如标题、作者、状态、可见范围、发布时间,这些适合放数据库; 正文、图片、附件这类大内容,更适合放对象存储。
第三,成本和扩展性更好。 对象存储天然适合放大文本和文件,便宜、稳定、扩容简单。
第四,这个项目后面还要做知识问答和索引。 正文放在 OSS 后,后续索引服务可以通过内容地址去拉正文,做切片和向量化,这条链更顺。
数据库存“元数据”,OSS 存“正文和资源文件”,这是职责分离。
6. 为什么要在发布流程里进行预索引?ElasticSearch 那块
预索引的核心目的,是把原本用户第一次访问时才要做的重操作,提前到发布后完成。
在这个项目里,发布成功后会触发一次预索引,尤其是 RAG 那块,会把正文拉下来、切片、写进向量库。 这样后面用户第一次提问时,就不需要现场建索引了,响应会更快。
如果不做预索引,会有两个问题:
第一,冷启动问题。 用户第一次搜索或者第一次问答时,系统还得现拉正文、现切片、现写索引,体验会差很多。
第二,重操作和在线请求耦合。 如果把建索引放到用户请求里做,请求时延会很大,而且更容易失败。
所以发布时预索引,本质上是在做一件事:给
把“重计算”前移,把“用户等待”后移。
计数系统
1. 为什么要单独将计数模块抽离出来?有什么好处?
这个项目里我把计数单独抽成模块,核心原因是计数本身就是一个高频、独立、通用的能力。 像点赞数、收藏数、作者获赞数、发文数,这些都不是某一个业务独有的,后面搜索、详情、列表、个人主页都会依赖它。
如果把计数逻辑都散落在帖子、关系、搜索这些模块里,会有几个问题:
- 逻辑重复,后面不好统一改
- 高并发下容易各写各的,幂等和一致性不好保证
- 计数的存储模型、重建策略、异步链路都比较特殊,放业务模块里会把业务代码搅乱
所以我把它抽成独立模块后,好处主要有四个:
- 统一能力出口 点赞、收藏、批量读计数、用户维度计数都走统一服务
- 方便做高并发优化 比如位图、消息聚合、快照重建,这些优化只做一套
- 方便扩展 以后加评论数、转发数,只要扩展计数模块,不用改很多业务代码
- 降低耦合 业务模块只关心“加多少、读多少”,不关心底层怎么存
计数是通用基础设施,不是某个业务页面的小功能,所以适合独立抽层。
2. 为什么选择 Redis 作为底层存储系统?有什么优势?可靠吗?
因为计数场景本质上是热点读写,要求低延迟、高并发和原子更新,Redis 天然适合做这个。它的优势是读写快、支持位图、自增、Lua 脚本这类原子能力,还适合承接中间态和快照;但我不会把 Redis 当成唯一真相来源,所以可靠性不是只靠 Redis 本身,而是靠 Redis 持久化、高可用,再加位图纠偏、Kafka 回放、快照重建这些机制一起保证。也就是说,Redis 适合做在线存储,但一定要配合恢复手段。
设计。
3. 讲一下 Redis 存储计数的实现细节。
这个项目不是简单做一个点赞数加一,而是分了三层:
第一层是事实层,用位图记录某个用户是否点过赞或收藏,保证幂等;
第二层是聚合层,用户动作产生增量事件后发到 Kafka,再由消费者先写进 Redis 的 Hash 聚合桶;
第三层是快照层,后台定时把聚合桶里的增量刷到固定结构的计数快照里,平时查询优先读快照,快照异常再按位图重建。所以整体思路是写入看事实,读取看快照,异常时能纠偏
4. SDS 是什么?为什么用固定结构字符串,不用 Hash 存多个字段?
这里的 SDS 你可以理解成 Redis 里的一个固定结构字符串,我们自己约定每 4 个字节放一个计数字段,比如点赞数、收藏数分别放在不同偏移位置。之所以不用 Hash 做最终快照,是因为固定结构更紧凑、更省内存,而且读一个 key 就能拿到整组计数,适合详情页和列表页这种高频读取场景;而 Hash 更适合做聚合桶这种中间态,因为它灵活但额外开销更大。所以这个项目里是 Hash 存中间增量,固定结构字符串存最终快照。
聚合桶指的是啥
面试版本:
聚合桶你可以理解成 Redis 里专门用来“临时攒增量”的一个地方。比如一篇内容短时间内来了很多点赞、收藏,我不会每来一次就立刻去改最终总数,而是先把这些变化量累计到这个桶里。像点赞就加 1,取消点赞就减 1,先按内容维度攒起来,后面再由异步任务批量刷到最终的计数快照里。这样做的好处是能把很多零散的小写操作合并掉,减少对最终计数的频繁更新,降低 Redis 写压力,也更适合高并发场景。
详细版本:
聚合桶就是 Redis 里的一个 Hash,key 类似 agg:v1:{entityType}:{entityId},field 是指标位点,比如 like/fav,value 是这段时间累计的 delta。它的作用不是长期存储最终值,而是把高频小写入先聚合起来,再批量刷到 SDS 快照,减少对最终计数结构的频繁改写。
5. 为什么要位图分片?分片大小怎么选?
因为如果一篇内容的所有用户状态都打在一个大位图 上,key 会越来越大,热点也会特别集中,所以我做了位图分片,按用户 ID 算出 chunk 和 bit,把一个大位图拆成多个小位图。这样既能避免单 key 膨胀,也能降低热点集中问题。至于分片大小,这个项目选的是 32768 位,也就是 4KB 一个分片,主要是平衡内存占用、统计效率和分片数量,太小分片太多,太大单 key 又会变重,所以这是一个工程折中。
6. 如果 Redis 宕机了怎么办?那你计数不是丢了吗?
分两层回答。第一层是基础设施层面,Redis 本身要有持久化、主从和高可用,这是基础;第二层是应用层面,这个项目没有把 Redis 快照当成唯一真相,而是保留了位图事实层和 Kafka 历史增量事件,所以快照坏了可以根据位图重建,严重一点还能通过 Kafka 历史消息做灾难回放。
7. 讲一下你这个计数恢复的重建策略吧。
这个项目里我做了两套恢复策略。第一套是读时重建,也就是查询快照时如果发现 key 不存在或者结构异常,就触发重建,先限流、退避、抢分布式锁,再去扫位图分片求和,最后回写新的快照并清理聚合字段;第二套是灾难回放,也就是在严重故障场景下,通过独立消费组从 Kafka 的最早位点开始回放历史计数事件,直接把快照重新折叠出来。前者适合局部纠偏,后者适合全量恢复。
8. 你提到用分布式锁防止并发回源风暴,具体讲讲。
场景是这样的,如果一个热点内容的计数快照坏了,很多请求同时进来都会发现快照缺失,如果大家一起去扫位图重建,就会把 Redis 打爆,所以这里必须做并发收敛。我采用的是三层保护:先做退避,避免失败后立刻反复重建;再做限流,控制同一个实体的重建频率;最后加分布式锁,真正拿到锁的线程才执行重建,其他线程直接走兜底值或者等待下一次读取。这样就把“所有人一起重建”变成了“最多一个实例重建”。
9. Redis 计数落库失败怎么办?
“落库失败”其实主要是两种 情况:
一种是 Kafka 消费后写聚合桶失败,这时我不会提交位点,后面还能继续重试;
另一种是聚合桶刷快照失败,这时我不会删除聚合桶里的字段,下一轮定时任务还会继续刷。也就是说,这套方案的核心不是失败后立刻补偿,而是先保证消息和增量不丢,后续还能反复处理,最终做到一致。
10. 计数怎么做幂等的?会重复加吗?
这个项目里幂等不是靠最终总数做的,而是靠前面的事实层做的。点赞和收藏先改的是位图,位图记录的是“这个用户当前是不是已经点过”,所以只有状态真的发生变化,比如从没点赞变成已点赞,或者从已点赞变成未点赞,才会发计数事件;如果用户重复点点赞,位图状态没变化,就不会重复发事件,也就不会重复加一。所以正常情况下不会重复加,后面再通过手动确认、聚合字段删除和重建机制做兜底。
综合问题
1. 你项目中有什么亮点吗,可以简单讲讲。
这个项目我觉得亮点主要有三块:第一,发布链路做了渐进式设计,草稿、正文上传、元数据补充、正式发布是分阶段完成的,稳定性更好;第二,计数系统不是简单自增,而是做了位图事实层、消息聚合层和快照层,既扛高并发又能重建;第三,内容侧把搜索和知识问答串起来了,发布后会触发预索引,后面无论是全文检索还是问答体验都会更好
2. 项目中如何处理高并发的?挑一个部分讲讲。
我就拿点赞计数这块讲。这里不是请求一进来就直接改总数,而是先在 Redis 位图里原子切换用户状态,只有状态真的变化才发消息;然后通过 Kafka 把增量异步送到聚合层,消费者先写增量桶,再定时刷快照。这样做的好处是同步链路很短,写压力不会直接打到最终计数上,而且重复点击也不会重复加。再往后如果快照异常,我还加了限流、退避和分布式锁,避免热点内容在重建时把系统打爆。所以这块高并发处理的核心思想是:同步链路只保事实,最终结果异步聚合,异常再做并发收敛。
讲一个难点和问题
点赞和计数。难点是高并发下既要防止重复点赞导致重复计数,又不能每次都直接更新总数,否则写放大会很大。我的做法是:写路径先用 Redis Bitmap + Lua 做原子置位,保证幂等;成功后发 Kafka 增量事件;消费者先写 Redis 聚合桶,再定时刷到 SDS 计数快照;如果快照缺失或损坏,就从 Bitmap 分片按需重建。这样写快、读也快,代价是接受秒级最终一致。
怎么写放大?
你明明只做了一次很小的业务写操作,但系统底层为了完成这次操作,额外产生了很多次真实写入。
用户点一次赞,本质上只是“一个用户对一篇内容的状态从 0 变成 1”。
如果设计得不好,可能会同时触发这些写:
- 更新点赞关系表
- 更新内容总点赞数字段
- 更新作者获赞数字段
- 删首页缓存
- 删详情缓存
- 删作者主页缓存
- 写消息队列
- 记日志或埋点
这样一次点赞,业务上是 1 次写,底层却变成了很多次写,这就叫写放大很大。
为什么不好:
- Redis/MySQL/Kafka 压力都会增大
- 并发高时容易成为瓶颈
- 一致性处理更复杂
- 延迟会变高
3. 项目里面的架构设计是从哪学的?
4. 高可用相关:MySQL、Redis、Caffeine 如何保证一致性的?
这个项目里我对一致性的理解不是绝对强一致,而是分层保证。MySQL 主要存业务主数据,是最终业务来源;Redis 承担热点缓存、计数快照和中间态;Caffeine 是应用内本地缓存,目的是减少重复查远端。处理上,我会把写请求先落业务主链路,再做缓存失效或旁路更新;本地缓存只做短时缓存,失效时间会更短,避免脏数据长期滞留;像计数这种本身允许短时间最终一致的场景,就通过消息、重试和重建来兜底。也就是说,这里不是追求“三层同时强一致”,而是通过主数据可靠、缓存短 TTL、更新链路可恢复,来保证业务上可接受的一致性。
5.你项目中点赞和关注这种都是异步写,那用 Kafka 投递消息的时候,Kafka 挂了怎么办?消息会丢吗?
这个场景要分生产和消费两端看。生产端我开了严格确认、重试和幂等,尽量保证消息写进 Kafka 才算成功;消费端是手动提交位点,只有真正处理成功才确认,所以消费失败不会轻易丢消息。严格来说,Kafka 挂了时,如果生产端根本发不进去,那这条异步链路就会受影响,所以生产环境一定要依赖 Kafka 集群高可用,而不是单点;但只要消息已经进入 Kafka,后面消费者失败是可以重试的,不会随便丢.Kafka 不是保证永远不出故障,而是保证故障后消息尽量不丢、能补、能重试。
你的项目中有对缓存雪崩、缓存击穿、缓存穿透做预防和处理吗?怎么做的? 有,而且是按问题分别处理的。缓存雪崩这块,我主要靠不同层级的短 TTL、错峰过期和本地缓存兜底,避免大量热点 key 同时失效;缓存击穿这块,在计数快照和热点内容重建时我加了分布式锁、退避和限流,避免一个热点 key 失效后大量请求一起回源;缓存穿透这块,主要靠参数校验、业务层判空和不存在结果的短缓存来减轻无效请求。
6.自己做的过程中遇见过什么难点或者卡点吗?怎么解决的?
这个项目里我印象最深的难点主要有两个。第一个是计数系统的一致性和幂等,因为点赞、收藏这种操作并发高,而且用户会重复点击,如果直接改总数,很容易出现重复加、丢增量或者快照不准的问题。后来我把这块拆成了三层:先用位图记录用户是否点过,这是事实层,只有状态真的变化才往后发消息;然后通过 Kafka 做异步聚合;最后把结果刷到 Redis 快照里供快速查询。这样正常情况下读写性能能扛住,高并发下也不会重复加。再往后我又补了异常恢复能力,如果快照丢了或者结构异常,就按位图重建,严重一点还能通过 Kafka 历史消息回放恢复。第二个难点是发布链路和内容索引的衔接。这个项目正文不是直接落数据库,而是先上传到对象存储,再回传元数据,最后发布后还要做预索引,给搜索和知识问答用。这里比较容易出问题的是状态切换和触发时机,比如草稿阶段能不能索引、发布后什么时候预索引、内容更新后怎么避免重复建索引。后来我的处理是把流程拆清楚:创建草稿、确认正文、补元数据、正式发布,每一步职责单独明确;索引这边通过内容指纹做幂等判断,没变化就不重复建。整体上我解决问题的思路是先把“唯一可信事实”找出来,再把重操作异步化,同时给异常场景留重试和恢复通道。
5000 万数据怎么从接口 A 发到接口 B
如果是 5000 万数据从接口 A 发到接口 B,我肯定不会一条一条同步去调,那样太慢也不稳定。我的做法一般是先把数据按主键范围或者时间分段,分批去拉,每批控制在一个合适的量,比如几千条,然后开多线程并发去发送,这样吞吐会高很多。这个过程中发送端和接收端都要做好幂等,避免重复投递把数据写乱;失败的批次要单独记录下来,后面重试。再大一点的数据量,我会更倾向于走消息队列或者专门的数据同步链路,而不是靠普通接口硬推,因为 5000 万这种量级,本质上已经更像数据搬运问题,不适合纯同步接口来扛。